
Sie sind bekannt wie ein bunter Hund, werden verteufelt und als Gefahr angesehen: Deepfakes. Wir wollen für sie eine Lanze brechen und einmal ergründen, welchen positiven Beitrag sie als Technologie leisten könnten. Wie Deepfakes funktionieren und welche technischen Möglichkeiten sie Kreativen zukünftig bieten könnten, erfahrt ihr in diesem Blogbeitrag.
„Machine Learning“ und „Deepfakes“ sind Schlagworte, die seit über einem Jahr Fuß gefasst haben und derzeit in aller Munde sind. Nicht zuletzt, weil Deepfakes auf politischer und medialer Seite bereits dämonisiert wurden, bevor sie überhaupt einen Status als sinnvoll anwendbare Technologie erreicht haben. Nichtsdestotrotz sind Deepfakes vielleicht sogar ein Blick in die Zukunft – zumindest ein Blick in die Zukunft der visuellen Effekte und Bewegtbilder.
Doch was sind Deepfakes?
Deepfake ist der Begriff für eine spezielle Art von Face Replacements, die in Bewegtbild-Medien angewandt werden kann. Eine optische Spielerei, die in Standbildern via Photoshop durch weniger als 5 Klicks erreicht werden kann – in Bewegtbildmedien aber sehr viel komplexer wird. In der Praxis gibt es viele Beispiele für notwendige Face Replacements.
Deepfakes: Beispiele für technische Möglichkeiten
Besonders bei amerikanischen Spielfilmen sind Face Replacements und ähnliche Tricks quasi an der Tagesordnung. Zum Beispiel, um verstorbene Schauspieler wie Brandon Lee („The Crow“, 1994), Peter Cushing („Rogue One“, 2016) oder Paul Walker („The Fast and the Furious 74“, 2013) in ihren Paraderollen zu präsentieren und die einzelnen Filme fertig zu stellen, bzw. im Falle von Peter Cushing & Carrie Fisher in „Rogue One“, ihre jüngeren Ichs ein letztes Mal auf die Leinwand zu bringen.
In der Vergangenheit waren diese Versuche von mäßigem Erfolg gekrönt. Brandon Lee wurde in „The Crow“ oft durch ein Double ersetzt, das sich tief in den Schatten der Scheinwerferlampen verborgen hielt, um nicht zu sehr aufzufallen. Paul Walkers digitales Double im Jahr 2013 konnte immerhin schon etwas Sonnenlicht genießen, da die Filmemacher den echten Bruder von Paul Walker als „Stand-In“ verwenden konnten. Die optische Ähnlichkeit in Gesicht, Körperbau und Performance erleichterte den Prozess etwas. Das Ergebnis war dabei… durchwachsen, um es mal optimistisch auszudrücken. Da Paul Walker zum Zeitpunkt seines Todes aber schon viele Shots des Filmes abdrehen konnte, waren die wenigen CGI-Replacements kein Beinbruch.
Das Uncanny Valley lässt grüßen
Ganz im Gegenteil dazu sind die Darstellungen von Peter Cushing als Grand Moff Tarkin und Carrie Fisher als Prinzessin Leia in „Rogue One“ inzwischen als prototypische Vertreter des „Uncanny Valley“ bekannt geworden.
Anm. des Autors: Das Uncanny Valley ist Synonym für eine Akzeptanzlücke bei künstlichen Figuren. Je menschenähnlicher eine (digitale) Figur ist, desto realistischer muss ihre Darstellung sein, um Akzeptanz zu schaffen. Bei künstlichen Menschen müssen also auch Gesichtszüge, Mimik und Bewegung stimmen. Sonst kommt so was bei raus:

Mehr zum Uncanny Valley für Wissbegierige:
Es ist also sehr schwierig, einen Menschen auf digitaler Eben zu imitieren. Wie wir aber bereits gelernt haben, ist es eigentlich sehr leicht, das Gesicht eines Menschen auf einer Fotografie auszutauschen. Deepfakes sind die Optimierung dieses vereinfachten Prozesses, der uns bereits tausende YouTube-Videos beschert hat, in denen Adolf Hitler und Josef Stalin neckisch „Video killed the Radio Star“ singen oder eine alternative Realität bieten, in der Sylvester Stallone als Kevin McCallister gecastet wurde.
Aber wie funktionieren Deepfakes denn nun?
Im Gegensatz zu den vollständig 3D-modellierten Köpfen, die wir eben behandelt haben, wird das neue Gesicht vom alten Schauspieler quasi als Maske getragen. Für den Prozess, der hierfür notwendig ist, ziehen wir dieses Beispiel von Freddie Mercury und Rami Malek heran, das von einem bekannten Deepfake-YouTuber erstellt wurde:
- Zunächst wählen wir eine Sequenz aus, in der das Gesicht des Schauspielers gut erkennbar ist.
- Im Anschluss wird das Gesicht des Schauspielers (Rami Malek) komplett freigestellt und als Einzelbilder exportiert.
- Jedes Einzelbild wird nun als Basis in eine speziell hierfür vorgesehene Software importiert.
- Als nächstes kommt der größte Teil des Aufwandes. Hierfür durchforsten wir das Internet, alte VHS-Kassetten und jede andere mögliche Quelle nach Videoaufnahmen von Freddie Mercury. Jede Aufnahme hilft. Denn jedes einzelne Bild von Freddie Mercury muss ebenfalls freigestellt und in unsere Software geladen werden. Diese Aufnahmen bilden unsere Mercury-Gesichts-Datenbank. Je mehr Bilder, desto besser! Dieser Prozess nennt sich „Machine Learning“. Denn wir bringen unserer Software damit bei, wie das Gesicht von Freddie Mercury aussieht. Und je mehr Pixel der Software zur Verfügung stehen, desto besser ist der Lerneffekt.
- Wenn alle Aufnahmen fertig sind, kann die Software mit der eigentlichen Arbeit beginnen. Es werden nun alle Aufnahmen von Rami Malek mit dem Gesicht von Freddie Mercury verglichen und die bestmögliche Entsprechung hierfür gesucht. Inzwischen sind die Programme so gut geworden, dass das Programm auch leichte Farb- und Lichtanpassungen vornimmt – was nicht bedeutet, dass nicht noch einiges manuell passieren muss.
Und das war es auch schon. Klingt simpel, ist natürlich aber trotzdem ein erheblicher Aufwand. Denn allein die Recherchearbeit hierfür ist enorm. Wenn auch dieser Aufwand zu groß ist, gibt es noch eine simple Version von „Deepfakes“. Mit dieser Methode kann man einem Schauspieler auch einfach ein Standbild eines Gesichts als digitale Maske aufziehen. Mit dieser Methode haben wir 2020 bereits in unserer Agentur experimentiert. Dabei haben wir herausgefunden, dass diese Methode zwar funktioniert, bei Personen, die sich nicht besonders ähnlichsehen aber schnell in Wohlgefallen zerfällt.
Gefahren und Konsequenzen durch Deepfakes- ein Gedankenspiel
Aber warum nun die 800+ Wörter zum Thema Deepfakes und Face Replacements?
Nun. Zum einen ist das Ganze ein spannendes Thema. Nicht nur technologisch, sondern auch moralisch und philosophisch. Adolf Hitler Popsongs aus den 70ern singen zu lassen ist irgendwas zwischen schräg und makaber. Zu sehen, wie Sylvester Stallone im Kinderkörper Fallen für Einbrecher stellt ist ganz unterhaltsam…
Aber was ist nun, wenn wir Videomaterial von Menschenrechtsverletzern Kriminellen oder Diktatoren sammeln und die Gesichter dieser Personen durch die Gesichter von Joe Biden, Angela Merkel o.Ä. ersetzen? Die Konsequenzen sind weitreichend. Denn zukünftige Generationen werden ganz schön verwirrt sein, wenn Samuel L. Jackson plötzlich die „I have a Dream“-Rede von Martin Luther King wiedergibt oder Elon Musk mit HAL 2000 spricht.
Deepfakes und Machine Learning: technische Entwickungsmöglichkeiten
Genauso spannend sind aber die technischen Möglichkeiten, die uns bevorstehen. Aktuell können wir mit Machine Learning recht gute Ergebnisse erzielen, weil das menschliche Auge auf so gut wie nichts anderes getrimmt ist, Gesichter zu erkennen. Auch wenn wir es nur unterbewusst wahrnehmen, ist unser Verstand messerscharf darauf eingestellt, minimale Veränderungen der Augenbrauen, Mimik oder Kopfneigung zu erkennen und zu deuten. Wir erkennen sogar Gesichter in Autos, Gullideckeln und den alten, braunen Schlieren-Fließen in Omas Badezimmer.
Aufgrund dieser evolutionären Umstände fällt es uns leicht, einem Computer beizubringen, was die definierenden Merkmale eines Gesichts sind. Augen, Augenbrauen, Mund, Nase, Punkt, Punkt, Komma, Strich – fertig ist das Mondgesicht.
Schwieriger wird es mit menschlichen Körpern, Bäumen, Landschaften oder abstrakten Konzepten wie „Gerüche“. Aber genau das könnte vielleicht das Ziel dieser Entwicklung sein.
Denn mal angenommen, wir können unsere Maschine mit tausenden Darstellungen von Straßen, Autos und Landschaften füllen, würde sich der nächste Audi-Werbespot quasi von selbst schreiben. Hierzu müssten wir lediglich eine Modelleisenbahn filmen, die wir mit der Hand über einen alten Pappkarton bewegen. Danach sagen wir unserer Software nur noch, dass sie die alte Spielzeuglock bitte gegen den neuen Audi, den Karton gegen eine Küstenstraße und die Hand durch die untergehende Sonne ersetzen soll. Fertig ist der Spot.
Oder warum überhaupt noch eine Kamera benutzen? Vielleicht würde es schon reichen, eine kurze Szenenbeschreibung an eine KI zu füttern und zu warten, was diese ausspuckt.
Und für wen das alles noch zu sehr nach fantastischer Zukunftsmusik klingt, für den habe ich an dieser Stelle noch eine schöne Überraschung: Denn dieses fantastische Hirngespinst ist bereits Realität!
Aus Text wurde Bild
KI-Entwickler haben unter deepai.org eine künstliche Intelligenz veröffentlicht, mit deren Hilfe man Text in Bilder umwandeln kann. Ja, richtig verstanden. Mit diesem Tool lassen sich echte Bilder aus einer Bildbeschreibung erzeugen! An dieser Stelle muss erwähnt werden, dass diese Bilder komplett neu erzeugt werden. Es funktioniert also nicht wie eine Suchmaschine, die anhand der Schlagworte ein Bild sucht, das zur Beschreibung passt. Stattdessen versucht die KI aus der eingegebenen Beschreibung ein passendes Bild zu generieren, indem es sich sozusagen alle passenden Beispielbilder ansieht und aus den Durchschnittswerten ein komplett neues Bild generiert.
Zur Veranschaulichung dieses Beispiels habe ich die AI mit der folgenden Beschreibung gefüttert: „Sports car on a beach with beautiful sunset in the background“. Keine vier Sekunden später gab mir die KI dann dieses wunderbare Bild von: einem Vogel ohne Gesicht, der auf trockenem Gras sitzt.
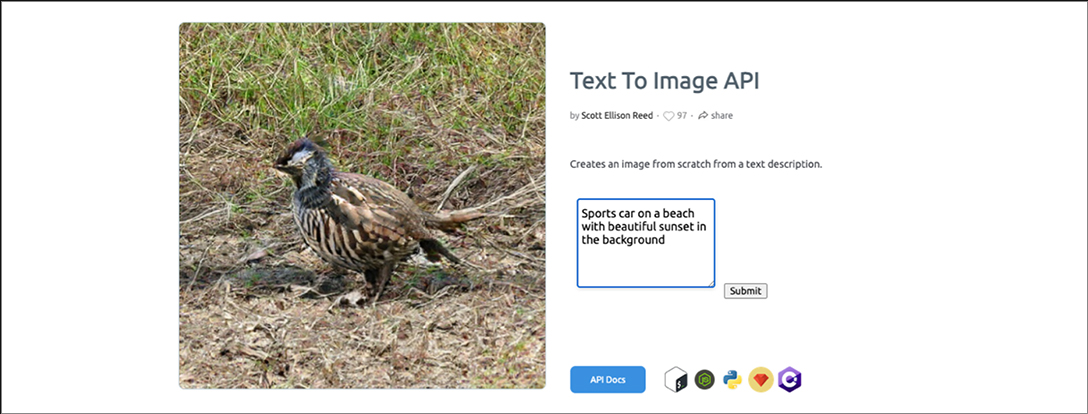
Tja. Ich kann an dieser Stelle nicht behaupten, dass das Ganze schon besonders gut funktioniert. Aber die Kollegen von OpenAI sind dafür schon auf einem ziemlich guten Weg. Das AI-Tool ist zum Zeitpunkt dieses Blogbeitrags noch nicht veröffentlicht, aber die „illustrations of a pikachu in a cape serving ice cream“ sehen schon jetzt vielversprechend aus.

Weitere Beispiele zum selbst Ausprobieren, sowie weitere Bildbeispiele gibt es auf der Seite von OpenAI zu bewundern.
Blick in die Zukunft: visuelle Effekte und Bewegtbilder
Aber: Abgesehen von der erhöhten Aufmerksamkeit, die wir jedem Videoclip in Bezug auf potenzielle „Fake News“ schenken müssen, welches Fazit ziehen wir nun? Dass der Beruf des Filmemachers und Fotografs in den nächsten 80 Jahren aussterben wird?
Nun. Das ist vielleicht die endgültige Konsequenz der Entwicklung. Spannender sind jedoch die mittelfristigen Möglichkeiten, die sich daraus ergeben. Facetracking-Technologien werden täglich einfacher; das „Ausschneiden“ und Einfügen von Bildelementen aus Bewegtbildern ist schon lange keine Hollywood-Magie mehr. Und das Austauschen von Bildelementen ist schon lange kein Grund mehr, um Projekttage in die Höhe zu treiben. Wir sind inzwischen an einem Punkt, an dem sich bereits mit wenig Aufwand Effekte erzielen lassen, die vor 20 Jahren noch ein Millionen-Budget erfordert hätten.
Es ist also DIE Zeit, um zu experimentieren! Produktdarstellungen vor Green Screen?
Kein Problem mit dedizierten Keying-Programmen, die das Freistellen einfach machen!
Personen freistellen und Motion Graphics im Hintergrund einfügen?
Kein Problem mit einer neuen KI, die das Freistellen von Personen in Bewegung zur Spazierfahrt macht!
Die Filmindustrie befindet sich im digitalen Frühling. Und die Blüten dieser Entwicklung machen sich bei Filmemachern jeden Kalibers bemerkbar. Hochwertige Werbespots, Imagevideos und Produktfilme müssen heute kein Vermögen mehr kosten, wenn man mit cleveren Lösungen und künstlicher Intelligenz arbeitet.

